本文源码请见我的GitHub
2.8.1 Numpy中的快速排序:np.sort 和 np.argsort
1 | import numpy as np |
1 | x = np.array([2,1,5,4,3])#不修改原始数组的基础上返回一个排好的数组 |
array([1, 2, 3, 4, 5])
1 | x.sort() |
[1 2 3 4 5]
1 | #返回原始数组排好的索引值: |
[1 0 3 2 4]
沿着行或列排序
1 | rand =np.random.RandomState(42) |
[[6 1 9 3 3 7]
[9 7 4 9 4 5]
[2 9 6 3 3 1]
[2 7 1 0 6 3]]
1 | #对X的每一列排序 |
array([[2, 1, 1, 0, 3, 1],
[2, 7, 4, 3, 3, 3],
[6, 7, 6, 3, 4, 5],
[9, 9, 9, 9, 6, 7]])
1 | #对行排序 |
array([[1, 3, 3, 6, 7, 9],
[4, 4, 5, 7, 9, 9],
[1, 2, 3, 3, 6, 9],
[0, 1, 2, 3, 6, 7]])
1 | '''上述处理将行或者列当作独立的数组,任何行或列的值之间的关系将会丢失''' |
'上述处理将行或者列当作独立的数组,任何行或列的值之间的关系将会丢失'
2.8.2 部分排序:分隔
1 | #有时候不需要排序,二十找到数组中第K小的值:np.partition |
array([2, 1, 3, 4, 6, 5, 7])
1 | #也可以沿着多维数组任意的轴进行分隔 |
array([[1, 3, 3, 6, 9, 7],
[4, 4, 5, 9, 7, 9],
[1, 2, 3, 6, 3, 9],
[0, 1, 2, 7, 6, 3]])
2.8.3 demo:K个最近邻
1 | import numpy as np |
1 | X = rand.rand(10,2) |
1 | dist_sq = np.sum((X[:,np.newaxis,:] - X[np.newaxis,:,:]) ** 2 , axis= -1) |
1 | difference = X[:, np.newaxis, :] - X[np.newaxis, : , :] |
(10, 10, 2)
1 | sq_differences = difference ** 2 |
(10, 10, 2)
1 | dist_sq = sq_differences.sum(-1) |
(10, 10)
1 | dist_sq.diagonal() |
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
1 | nearest = np.argsort(dist_sq, axis=1) |
[[0 3 4 5 8 1 9 7 2 6]
[1 4 6 9 8 0 7 3 2 5]
[2 7 9 8 6 4 3 1 0 5]
[3 5 0 8 4 9 7 2 1 6]
[4 1 0 8 9 6 3 5 7 2]
[5 3 0 8 4 9 1 7 2 6]
[6 1 9 4 8 7 2 0 3 5]
[7 2 9 8 6 4 1 3 0 5]
[8 9 4 7 2 3 0 1 5 6]
[9 8 7 2 6 1 4 0 3 5]]
1 | K = 2 |
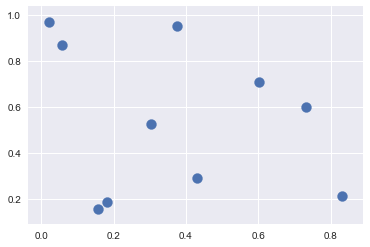
1 | plt .scatter(X[:,0],X[:,1], s= 100) |
<matplotlib.collections.PathCollection at 0x2a2fa444be0>
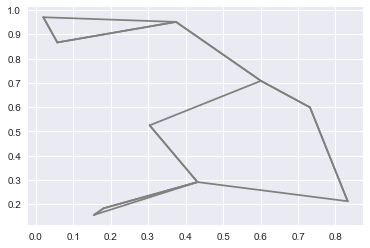
1 | #将每个点与他最近的两个点相连 |